Diese Anleitung ist rein Akademisch, keine Nachahmung empfohlen und ist von Seiten Apples nicht gestattet. Ich betreibe keine Downloads zu dem Thema und habe nach der Anleitung alle virtuellen Maschinen wieder gelöscht. Nachmachen auf eigene Gefahr und Verantwortung.
Zuerst laden wir uns den VMWare Player 17 herunter:
https://www.vmware.com/content/vmware/vmware-published-sites/us/products/workstation-player/workstation-player-evaluation.html.html
Dann das macOS Ventura (13) VMDK Image herunterladen: (eine VMDK ist fertig installiert, also ein „Clone“ von einer Festplatte, damit geht es schneller und vor allem es funktioniert! Man braucht nicht mühsam von einer .ISO das Betriebssystem zu installieren)
https://drive.google.com/file/d/1pKppcUCT6StvNGDeqwELyoLheNrilE_K/view?usp=sharing
https://drive.google.com/file/d/1XvYBTeFBNfU6lEjCoHl1YxlMbpjugA7H/view?usp=sharing
https://drive.google.com/file/d/1vSr7apfvIB0Ufq9SCDKhMgmILCuideWz/view?usp=sharing
Credits für die VM und den unlocker gehen an https://www.sysprobs.com/macos-13-ventura-vmware-pre-installed-image-download-windows-11-10?utm_content=cmp-true
Falls einmal die Downloads nicht mehr gehen, bitte mir eine kurze Nachricht schicken, ich kann euch dann auf einen alternativen google.drive.com verlinken.
Warum verlinke ich nicht gleich auf https://www.sysprobs.com?? Natürlich, damit Ihr a) weniger Werbung seht, b) die Anleitung nun auf Deutsch habt und c) ein „Mirror“ ist, für alle Eventualitäten und d) ich habe den Installationsvorgang sehr detailliert abgebildet, damit auch weniger PC begabte die Schritte nachvollziehen können. Aber bitte klickt bitte auf den oberen Link und macht einen Hit, damit sysprobs.com etwas davon hat!
Disclaimer: Die Bilder habe ich natürlich nicht von Sysprobs geklaut, das sind hübsch meine, die bitte nur mit meiner Erlaubnis verlinken/verwenden, vielen Dank!
Dann benötigen wir noch 7-Zip zum entpacken:
https://www.7-zip.org/download.html
Nun noch den VM Ware Player 17 und 7Zip installieren… das müsst Ihr hinbekommen, Spoiler: nachher wird’s noch schwieriger… oder Ihr lasst euch helfen?!
Dann laden wir uns noch den VMWare Unlocker herunter:
https://github.com/paolo-projects/unlocker/releases/download/3.0.4/unlocker.zip
Entpacken, nach unlocker, ich entpacke immer gleich im Download Ordner, danach lösche ich den Ordner wieder, nach getaner Arbeit.
Die Installation vom unlocker (keine Illegale Software, schaltet nur in der VMWare die Option macOS frei!!) soll erfolgen, wenn VMWare nicht läuft, sonst funktioniert das nicht. Also VMWare beenden, dann öffnet Ihr einen Explorer, klickt mit der rechten Maustaste auf „win-install.cmd“ und wählt „Als Administrator ausführen“…
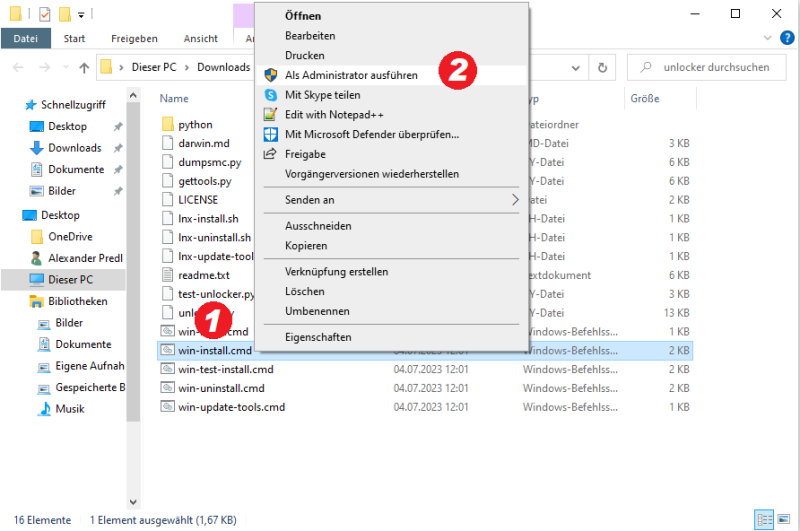
damit schaltet Ihr MacOS in VMWare frei, sonst könnt Ihr MacOS nicht installlieren…
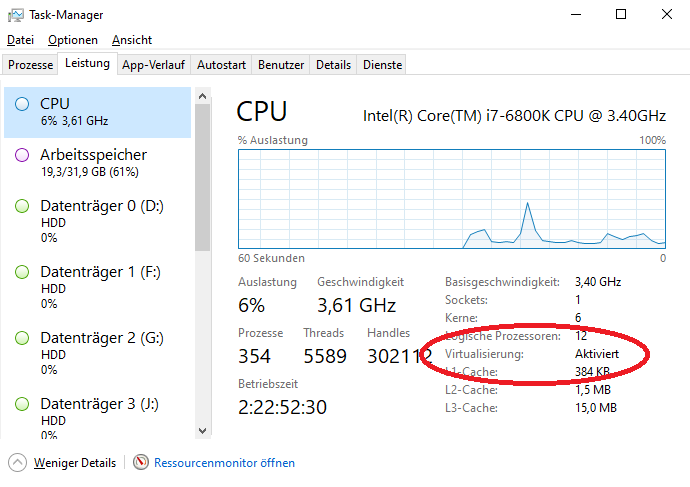
Öffnet den Task-Manager (STRG+SHIT+ESC), seht nach in „Leistung/CPU“ und schaut unten auf „Virtualisierung“, wenn dort steht „Aktiviert“ ist alles roger, keine Änderung notwendig, falls dort „Virtualisierung“ auf „Deaktiviert“ steht, müsst Ihr die VT-x für den Prozessor im BIOS einschalten, nur so funktioniert die VMWare. Virtualisierung aktivieren falls man Hilfe braucht.
So damit haben wir die Voraussetzungen und können loslegen:
Zuerst entpacken wir die 3 Image Teile, damit wir die .vmdk erhalten:
Wir kopieren alle 3 Teile in ein Verzeichnis, drücken die rechte Maustaste auf die erste ZIP Datei (.001) und wählen Extract to „macOS13_ventura\“
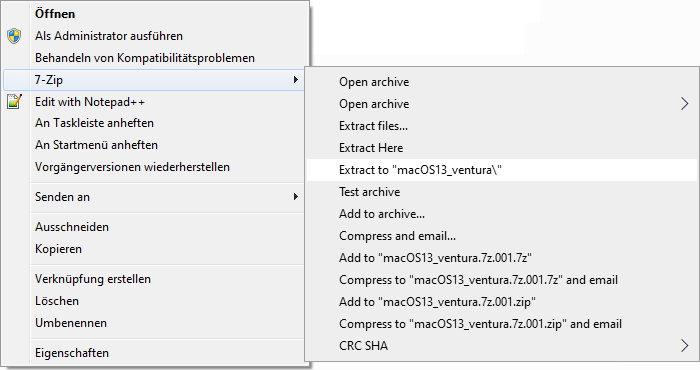
Im Verzeichnis macOS13_ventura sollte sich nun die macOS13_ventura.vmdk befinden!
Wir starten VMWare und erzeugen eine neue Virtuelle Maschine: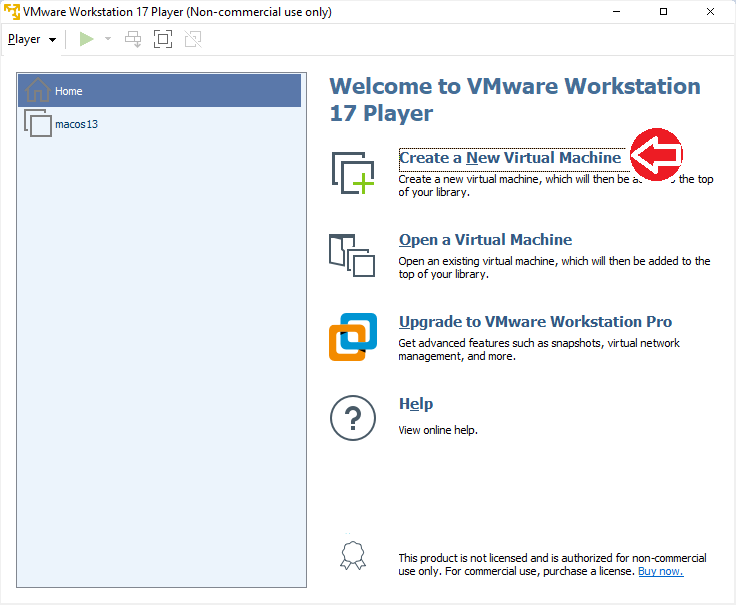
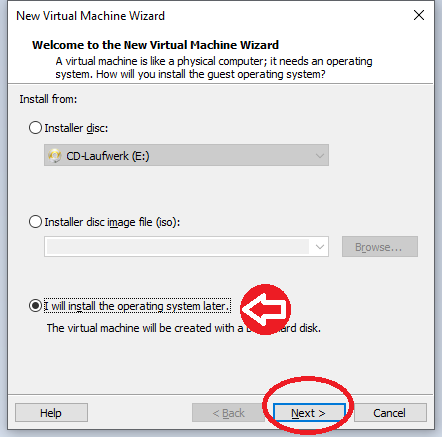
Dann wählen wir später installieren und drücken „Next“:
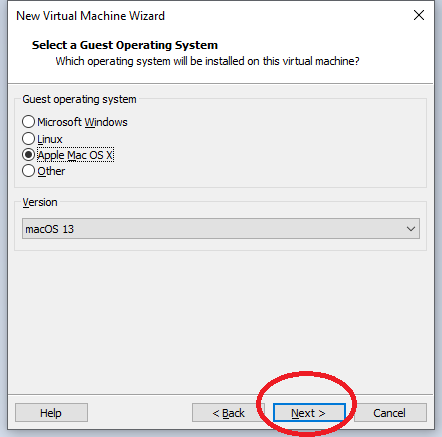
Dank des „unlocker“ Patches, können wir nun Apple Max OS X auswählen und „Next“ drücken:
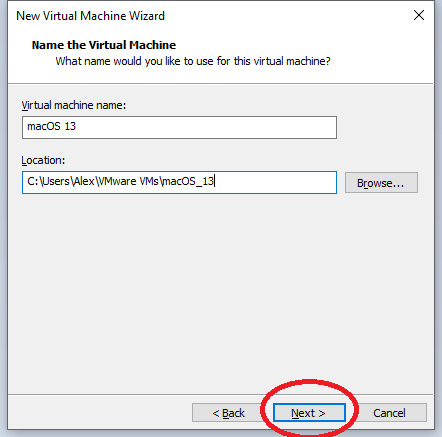
Nun können wir den Namen der VM bestimmen und auch den Speicherort und drücken „Next“:
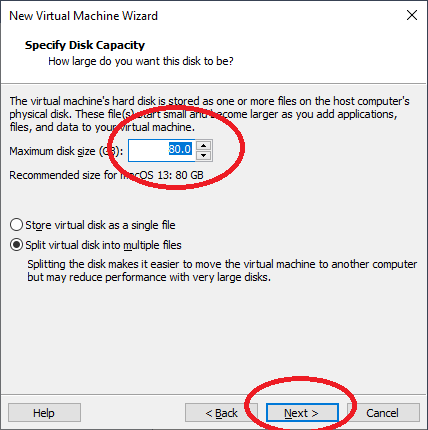
Dann die Festplattengröße festlegen, ist egal, wir tauschen dann diese Festplatte gegen unsere entpackte VMDK vorinstallierte Festplatte aus. Drücken Sie „Next“
So, dann auf „Finish“ drücken:
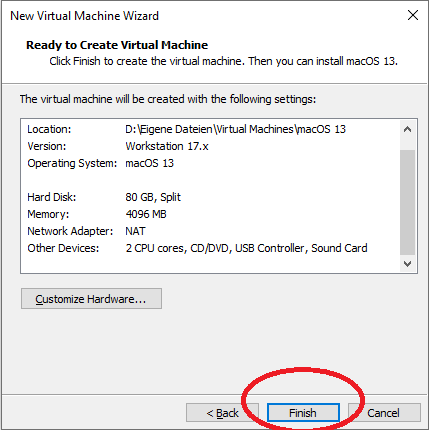
Nun ändern wir die neu erstellte Virtuelle Maschine, drücken Sie dazu auf den Namen „macOS 13“ oder so wie Sie die VM genannt haben und drücken unten auf „Edit virtual machine settings“
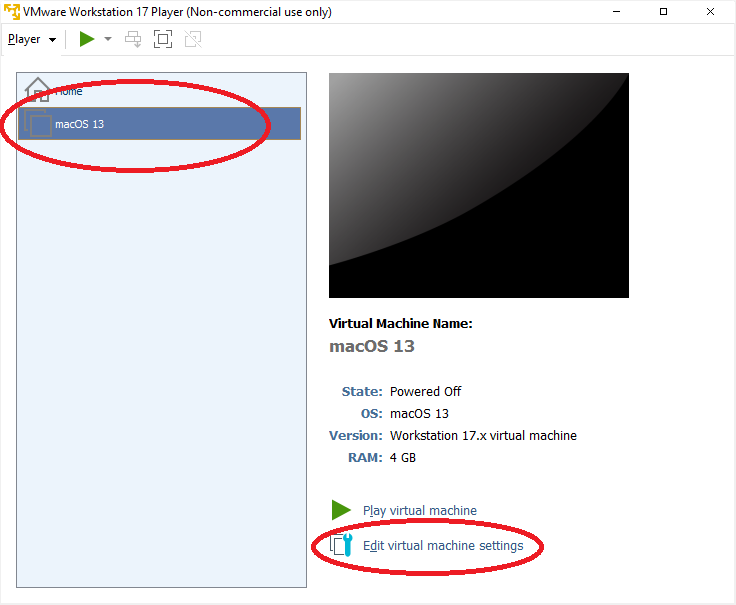
Nun ändern wir die Ram Größe auf 6144MB = 6GB Ram:
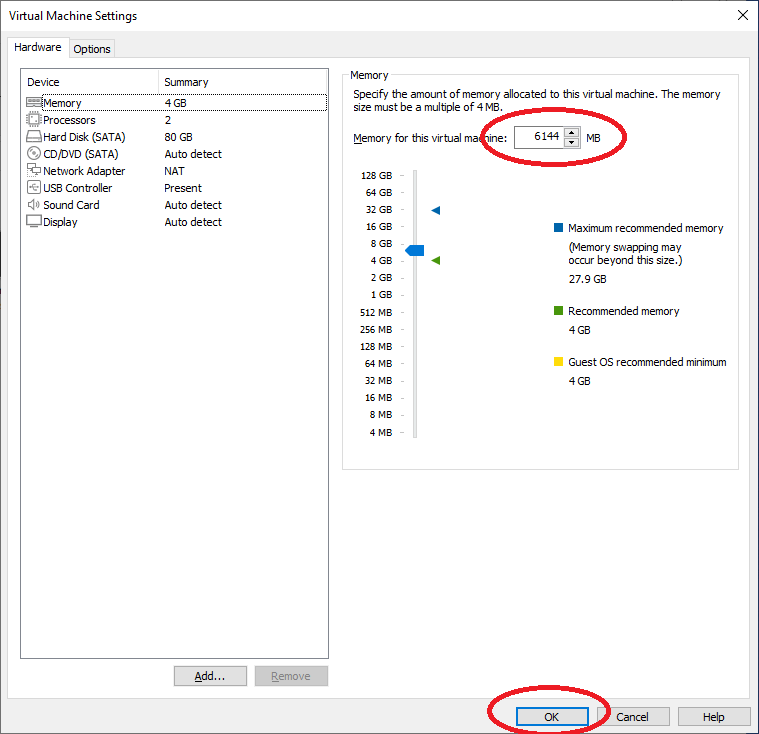
Dann ändern wir die Anzahl der Prozessoren auf 6:
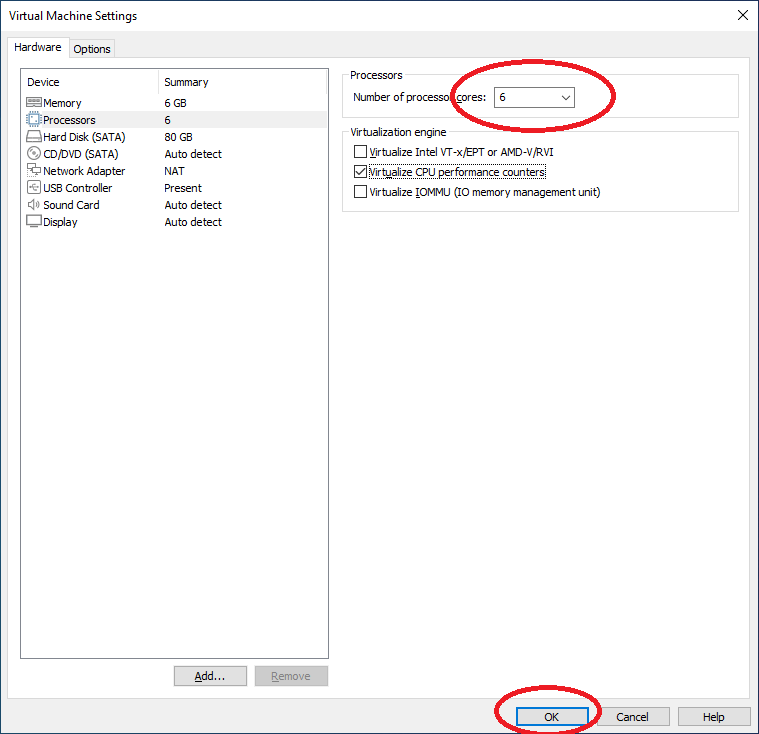
Nun fügen wir die Festplatte hinzu, wählen Sie Hard Disk (SATA) und drücken Sie unten auf „Add“:
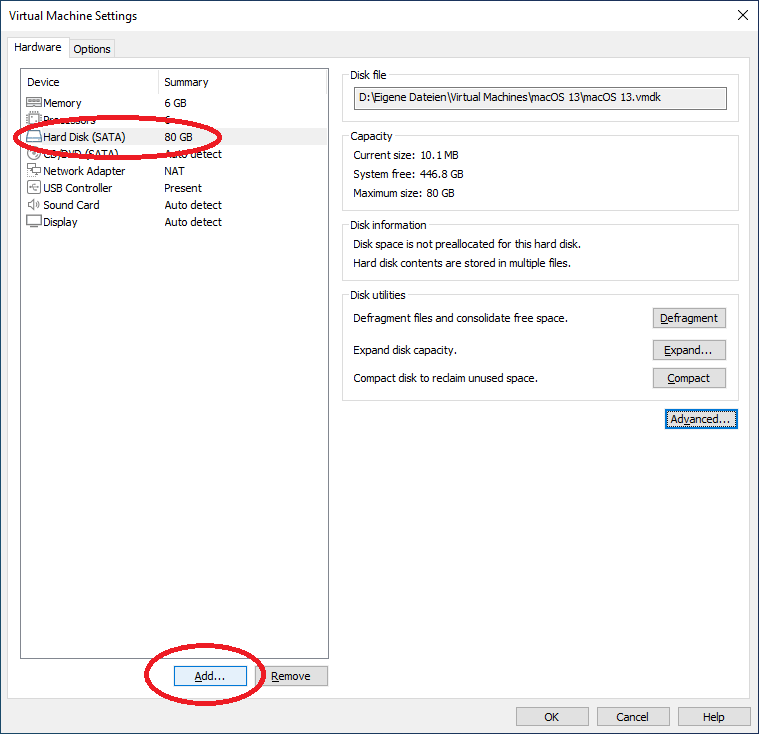
dann wählen wir Harddisk und drücken auf „Next“
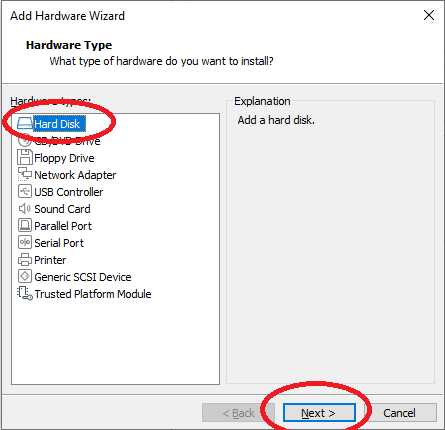
Wählen Sie SATA und drücken Sie auf „Next“:
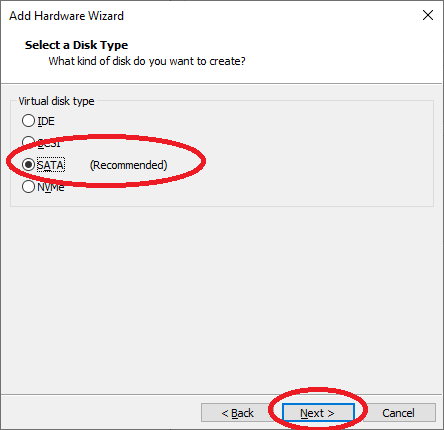
Im nächsten Bildschirm wählen Sie „Use an existing virtual disk“ und drücken auf „Next“:
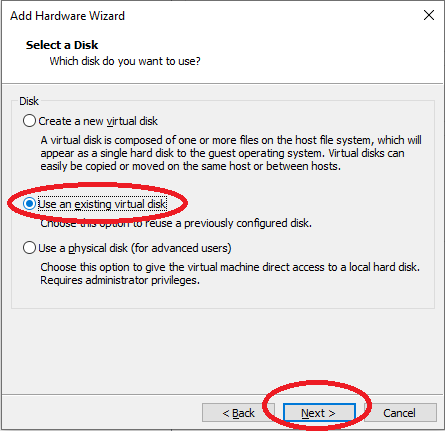
Wählen Sie nun die heruntergeladene VMDK aus und drücken Sie auf „Finish“:
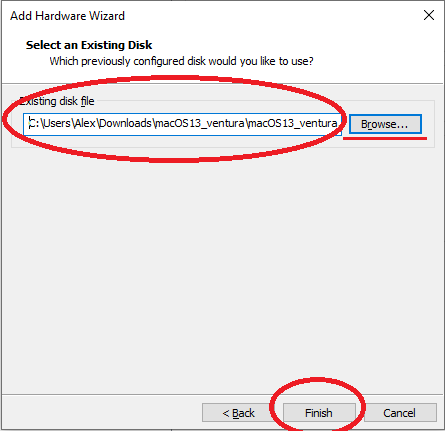
Nachdem die VMDK schon älter ist (VMWare 16) kann man diese noch auf das neueste Format bringen, das habe ich gemacht:
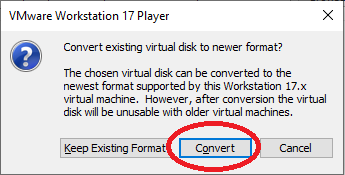
Man kann, muss man aber nicht, die Größe von 60GB auf 80GB oder größer nun verändern, das kann man mit dem Button „Expand“, einfach die neue Größe eingeben, macOS verwendet dann die neue Größe ohne die Partition ändern zu müssen.
Nun müssen wir nur noch die .vmx Datei ändern, dazu öffnen wir das Verzeichnis, wo wir die VM installiert haben, dazu können wir nochmal in den Virtual Machine Settings nachsehen, wo die VM vorhanden ist:
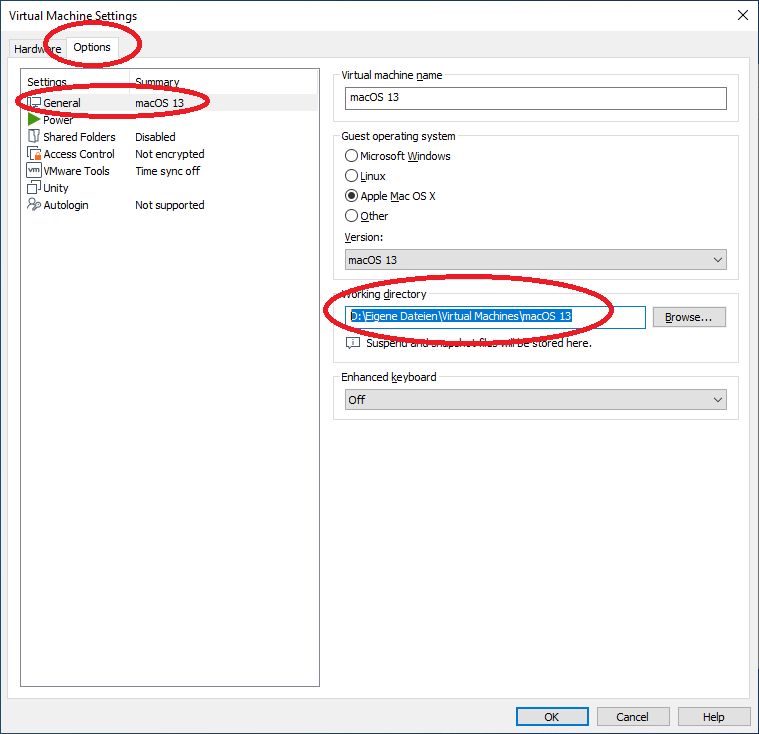
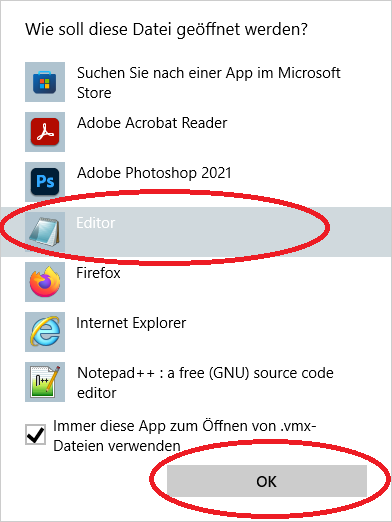
Diesen Pfad kopieren wir und setzen ihn im Adressfeld von einem Windows Explorer ein, dann drücken wir mit der rechten Maustaste darauf und wählen „Öffnen mit“:
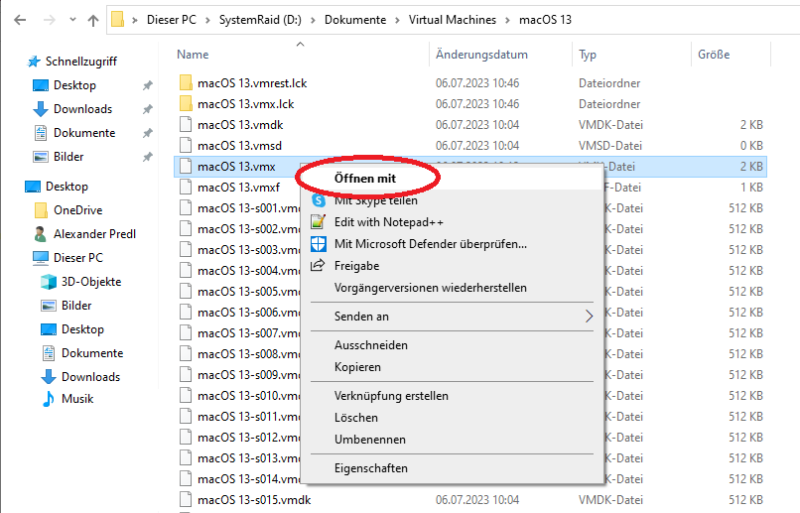
und wählen dann den Editor und drücken Ok:
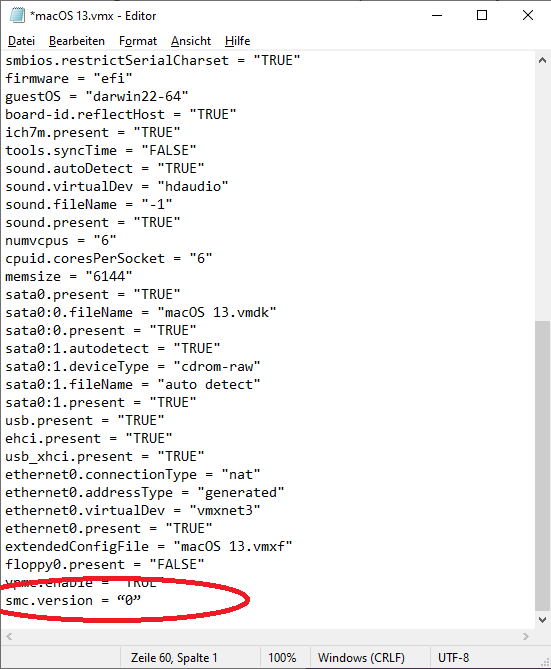
dann im Editor fügen wir ganz unten smc.version = “0” ein:
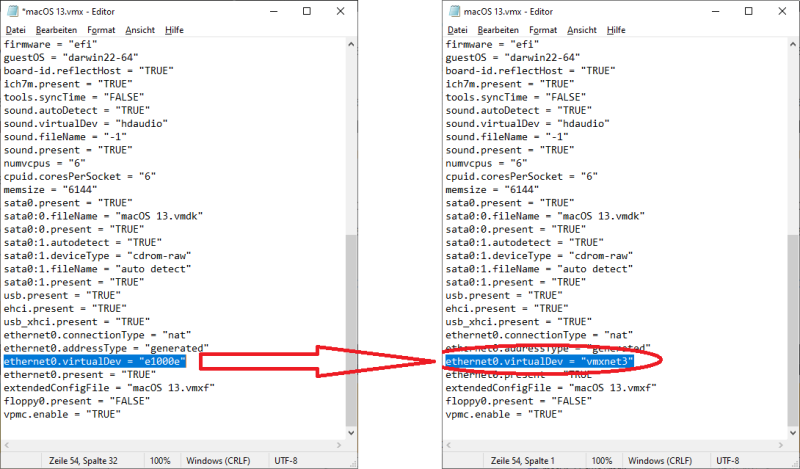
Im nächsten Schritt suchen wir nach „ethernet0.virtualDev“, den Eintrag müssen wir von ethernet0.virtualDev=“e1000e“ auf ethernet0.virtualDev=“vmxnet3″ ändern
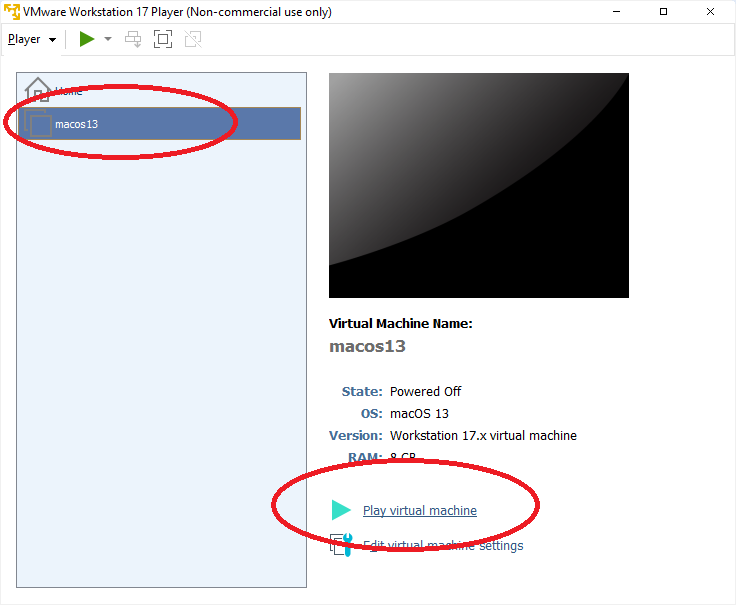
Speichern wir die Datei und wir können die VM starten:
das Passwort für den Sysprobs Benutzer Account lautet: sysprobs123: (wenn das Passwort falsch ist, probiert szsprobs123 (im Englischen sind Z und Y vertauscht!)
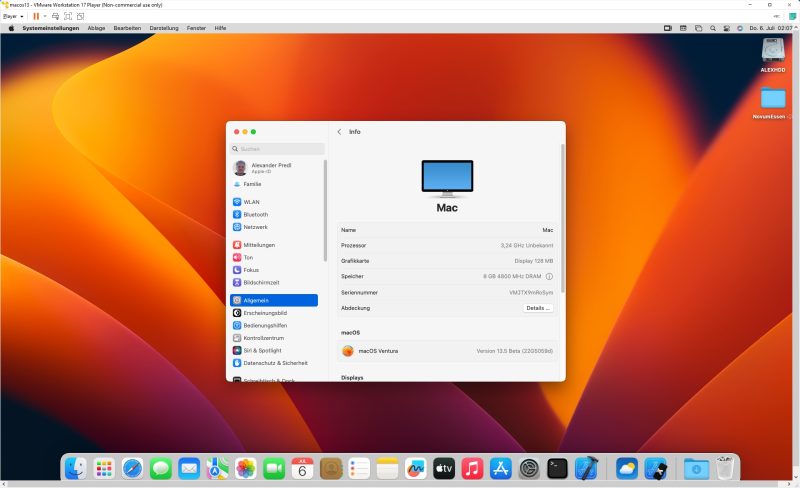
In der VM zuerst die Tastatur auf Deutsch umstellen, dann sich im Apple Account Anmelden. Der Klammeraffe @ ist auf der Apple Tastatur ALTGR+L statt ALTGR+Q
Kann man diese VM updaten z.B. später mal auf macOS 14 usw., JA
Kann man den Sysprobs Account ändern: JA (einfach einen neuen Admin Benutzer hinzufügen und den Sysprobs Account löschen)
Kann man das Passwort ändern, JA
Eigentlich kann man nun mit der funktionierenden VM so ziemlich alles machen was man möchte, mit XCode Programme schreiben, Handys verbinden (die USB einfach freigeben) usw. Den Bildschirm kann man größer anpassen, Vollbild geht auch, ich habe 3 Bildschirme, der linke ist dann für macOS.
Aja natürlich geht das ganze auch direkt am Mac, da ich einen mac mini late 2014 besitze und Xocde natürlich die Mindestanforderung macOS 13 hat, habe ich mich überhaupt darum bemüht, macOS 13 zum Laufen zu bringen. Mit VMWare Fusion kann man auch am Mac direkt, macOS 13 emulieren:
Disclaimer: Ich besitze einen Mac Mini darauf läuft macOS, ich habe diese Anleitung nur geschrieben, damit Andere macOS testen können, aber wenn man macOS benutzen möchte, sei es Privat, Beruflich oder gar in Firmem verwenden möchte, bitte kauft einen Apple Mac! Ich habe macOS nicht mehr in der VM laufen (nach dem Testen gelöscht) und distanziere mich von jedem finanziellem Interesse. Grundsätzlich ist der Betrieb und Installation von macOS auf einer nicht Apple Hardware untersagt und verstößt daher gegen die Bestimmungen von Apple!
Der Download ist von einem anderen User, der nicht mit mir verwandt oder mir bekannt ist, ich stehe in keiner Verbindung mit dieser Person. Falls eine Beanstandung dieser Links besteht, bitte um eine Nachricht auf office[add]predl.cc, ich werde diese umgehend entfernen.
Ich erhalte keine Finanzielle Unterstützung von irgendwem und werde auch nicht Werbefinanziert. Diese Seite ist ein Hobby Projekt und alle Anleitungen sollen nur als „Proof of Concept“ gesehen werden, nachmachen auf eigene Gefahr und Verantwortung.
Apple und macOS alle Rechte (Markenrechte und Copyright) liegen bei Apple Inc.One Apple Park Way, Cupertino, CA 95014.
Getestet unter Windows 10 und VMWare Player 17
Wie immer, alle Angaben ohne Gewähr, Anwendung auf eigene Gefahr und Verantwortung, ich übernehme keinerlei Haftung für Ausfälle, Datenverlust oder andere finanzielle Schäden. Die Links auf dieser Seite wurden von mir nicht überprüft, ich übernehme keine Haftung für die Inhalte.
Happy coding!